Procedural generation: begin with the end or begin with the beginning?
Last changed on
Even though I do not consider myself a procedural content generation specialist, I have worked on it enough to have encountered what I believe if one of its fairly common problems, expressed as a seemingly innocuous questions: where to start?
This question, although it may sound a bit ridiculous, is in fact a reflection on how generation will take place, and in which order:
- What is the engine trying to simulate?
- What are the engine's constraints and set of possibilities?
- What can be done to make the resulting procedural content feel reasonably realistic?
- Which, if any, are the hardware constraints?
- Which,
if any, are the personal knowledge & expertise constraints?
Add to this that you have to start somewhere, and suddenly the question is deeper and more complex than it had initially seemed to be.
Start with the beginning
Put very simply, this is the ideal solution as it tries to simulate an outcome based on circumstances. This can be anything from chemical composition and atomic interaction, distance and gravitional influences, all framed by our current knowledge of the universe, from the atomic scale and below to the universe scale.
It is the best solution as it starts from the origin and tries to determine how constituents interact with one another in order to create something different - an actual simulation! However, it comes with extreme costs:
- The level of expertise required in sometimes staggering: mathematics, physics, chemistry, gravitational influence (both classical and relativistic) all come into play and frankly -and even though I dabble in such things-, this is far beyond my knowledge. So that's our first problem.
- The hardware requirements can quickly become overwhelming: in spite of what can be achieved by extremely competent research teams (I insist on teams because yes, they are teams!), the hardware needed to run such simulations is enormous at best. We are sometimes talking about extensive farms of extremely high-end CPU, often paired with "cheap" GPUs such as the H100 or the V100… So that's problem number two.
- The example was used elsewhere a while ago, but simulating a full 3d convection model of an exoatmosphere is rather… slow. Even on said hardware. So performance becomes our problem number three.
Problem number one: people and expertise
Since I am not the unholy offspring of Einstein, Stephen Hawking and Superman, my knowledge is pretty limited. Of course unlimited money and/or unlimited enthusiasm by relevant and extremely specialised people, could fix the problem - but they are at best unlikely to happen. :-)
Problem number two: hardware
Sure, I could remortgage the house, sell the family heirlooms etc. and buy a monster farm of CPUs and GPUs. However, that would be a tad expensive compared to what the experiment currently runs on: a commodity server costing around 60 pounds a month. Full specs:
| CPU | Intel Xeon-D 2141I, 8/16 cores |
|---|---|
| RAM | 64 gigabytes |
| Disk | Soft raid 2*480 gigabytes |
| GPU | lolwhat? too expensive. When I come round to using 1+ of those, it will be custom-made, probably. |
| Network | Unlimited public bandwidth of 500 Mbit/s |
All in all a rather nice package for the price!
But back to the farm: in addition to its price (and maintenance!), would I even be able to use it to its full potential? I mean, buying a Ferrari without having a driver's licence is not very useful, is it? In other words, today's traffic on Ad Lumens does exist, but certainly does not justify such expenses.
Problem number three: performance
Going back to the 3D convection model or similar simulations, such as plate tectonics and 2+ body systems; assuming those can be done thanks to the two above problems being fixed, then what? Wait for 35 minutes for a procedural planet to be generated? Or 5 minutes for what's needed to generate a procedural texture?
By now, dear reader, you should be convinced that the "start from the beginning" is not really workable. Maybe it will be one day, one can hope. In the meantime, I though it would be could a good idea not to become stuck in a XY problem.
Start with the end
This all leads us to Ad Lumens's main choice: start from the end. I know it sounds a little absurd, but here are its general steps and principles:
- Get access to a lot of documentation on the subjects Ad Lumens is interested about: stars, planets, etc.
- Try and understand them and, even better, try to extract their conclusion and turn it into something tangible for the engine.
- Try and find a reasonable balance between realistic and playable/interesting in order to enrich the realm of possibilities opened to the engine
Documentation
The galaxy and more generally, the Universe, are complex places. Even when ignoring unknown players such as dark matter and dark energy, the complexity of interactions between everything that surrounds us is staggering. Hence the decision not to go the way chosen by people far more specialised than I am (and probably more useful than Ad Lumens too): scientists. :-)
The constant work done by scientists, from PhD students to seasoned researchers, is something that is of course incredibly valuable to us as a species. To Ad Lumens as well: the Internet is literally gorged with research papers on subjects and problems extremely relevant to the proceduratl generation of a galaxy.
Exoplanets, for example, as a big thing these days: the number of currently active exoplanet missions is proof of this, along with the ease with which one can find related papers on portals such as arXiv.
My search skills are not fabulous, but here are a couple examples of what one can come up with when some search and reading effort is made:
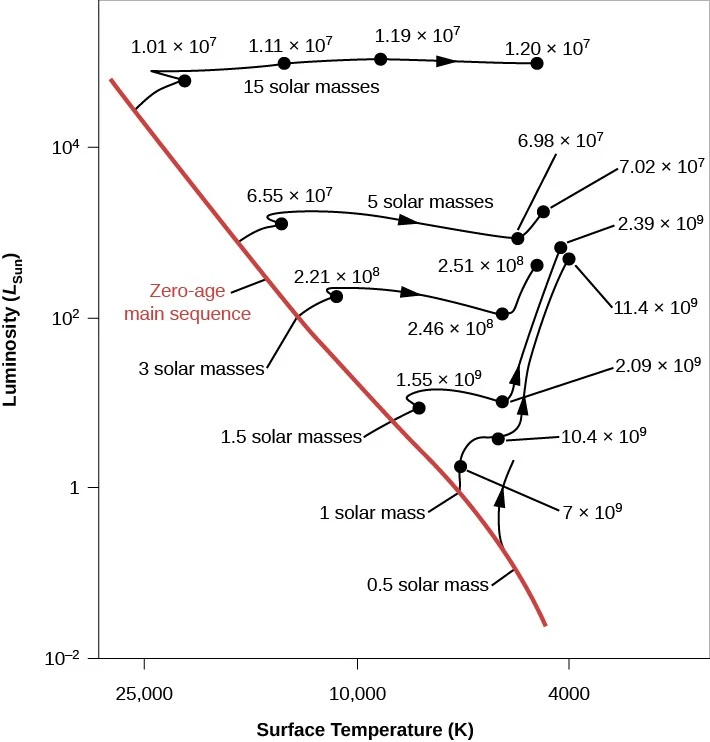
A simplified set of stars' evolutionary tracks: the relative simplicity of this graph enables the building of functions (even more simplified!) to simulate values actually observed in the Universe around us.
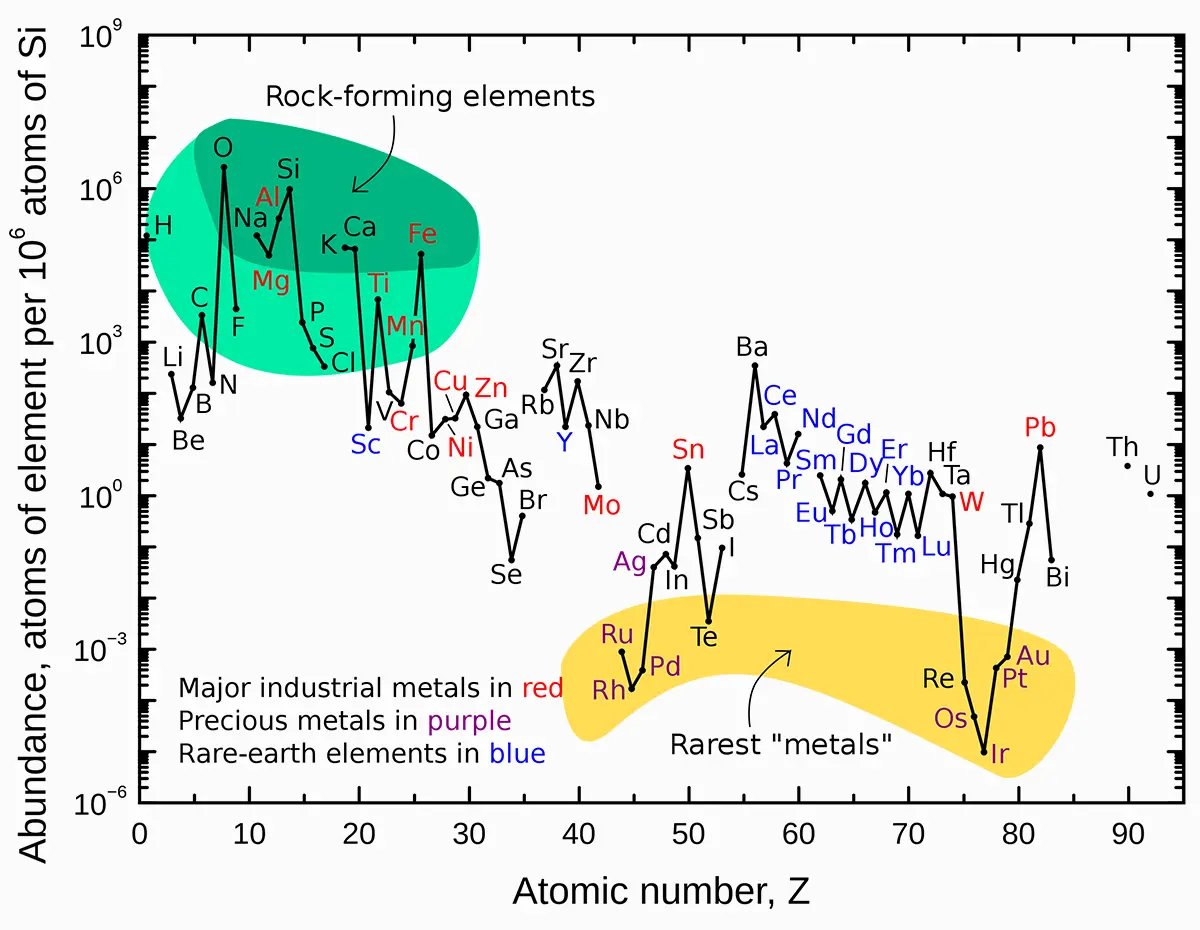
Here again, a person with highly developed and specialised skills compiled a graph whose usefulness to something like Ad Lumens cannot be overstated. This is an excellent base to start thinking about procedural planetary crust generation - at least in terms of building blocks!
Translation into engine food and balancing act: between realism and "gameism"
The second step is one of simplification. In other words: given what serious people have come up with, how can we simplify it so the game engine is able to process it all quickly. This also involves it being "easy to maintain", i.e., no coming back to the code 3 months later and think wtf was I thinking when I wrote that???.
Going back to the two example above:
Star evolutionary track
This graph is incredibly useful to:
- get a feel of the kind of changes stars undergo as they age
- understand when those changes happen relative to the individual star's lifetimes
- understand that changes of direction in the curves represent important state shifts
| Parameter/dimension | Observation and simplified version | Comments |
|---|---|---|
| Initial mass | We start from the randomly generated star initial mass | This is quite straightforward |
| Age | The graph indicates the "turning points" in a star's lifetime, which we simplify greatly | More often that not, straight lines between two points are used as they are much, much cheaper to compute and especially to derive as generic reusable functions. Less accurate, but in the vast majority of cases this proves to be acceptable |
| Giant phase | The hint is luminosity change for smaller masses | For many star masses, we skip the "Helium flash" and asymptotic branch phases |
| Overall slopes | Are useful when considering that the Y-axis is luminosity | A strong slope indicates a transition, more or less abrupt, between a main sequence end and a giant phase (Where we know luminosity increases massively) |
Planetary crust composition
Obviously this graph is based on what we know of Earth's crust. Which, by now, is fairly well known to us, due human activity, from mining exploitation to scientific surveys and ultrasound analysis.
Naturally, this does not necessarily apply to exoplanet crusts which, as far as I know, are utterly unkwnon to us. But that has not prevented serious people to work on the problem and, drawing parallels with planets closer to home (such as Mars, Venus or Titan), and to wonder why it would be so different from what can be found within our solar system.
The (far) future will tell (hopefully!), but in the meantime, Ad Lumens has chosen to adopt a cautious approach:
- Given the reasonable sample in our solar system, we assume all planetary crusts will kind of follow it
- This includes composition, level of acticity (plate tectonics, etc)
The end result is that each planet (telluric/rocky, of course) is randomly assigned a crust template at creation. Template characteristics do tend to respect the graph above, but only to a certain extent: some variability is needed, because variability is fun.
This template is maintained via the Django admin (as hinted at in this post) where it can be assigned various values:
- Compound abundances (From Olivine to Orthoclase and Witherite)
- Relative weight, which bluntly represents the chances for the template to show up. This is a nice opportunity to "go crazy" and, once in a rare while, insert a really alien crust into the galaxy. Note: at this moment, only a very few templates exist and active in the data explorer or 3D explorer, but several are actually in draft status.
Please signin to add your comment.